wtf: Why do we have picture AI now?
The Technology of Stable Diffusion
Stable Diffusion is a new type of AI model that generates high-quality images from text prompts. It can do video too as I've written about here. Just as a human artist creates visuals based on descriptions, Stable Diffusion can produce coherent and engaging images on virtually any topic. This capability is powered by a sophisticated architecture and a vast dataset, making it a versatile tool in the realm of AI-driven art and design.
The Diffusion Model
Stable Diffusion operates on a principle known as latent diffusion. Instead of working directly with high-dimensional pixel images, it compresses images into a lower-dimensional latent space. This significantly reduces the computational load, allowing the model to run efficiently even on consumer-grade hardware.
- Image Compression: The model starts by compressing an image into a latent representation using a Variational Autoencoder (VAE). This step captures the fundamental semantic meaning of the image in a much smaller space.
- Noise Addition: Gaussian noise is iteratively added to the latent representation, simulating the process of image degradation.
- Denoising: A U-Net architecture, equipped with a ResNet backbone, is used to reverse the noise addition process. This step-by-step denoising reconstructs the image from its noisy latent representation.
- Text Conditioning: The model can be conditioned on text prompts using a pretrained CLIP text encoder. This allows the generated images to align closely with the provided textual descriptions.
Transformers again!
I talked about Transformers before in THIS POST, you should read it first. At the core of Stable Diffusion's text-to-image generation capability lies in its use of the Transformer architecture. This architecture excels at capturing long-range dependencies and contextual relationships within text, making it ideal for understanding and generating complex descriptions. Imagine an artist starting with a blank canvas filled with random scribbles.
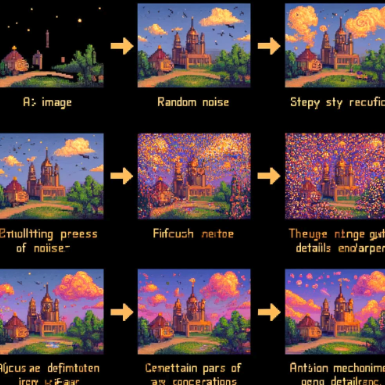
Stable Diffusion works similarly. It starts with an image full of random noise, essentially a chaotic mess of pixels. Over multiple steps, the model refines this noisy image, gradually turning it into a detailed and coherent picture. Here’s how it works:
- Initialization: The process begins with a noisy image. Think of it as a canvas covered in random dots of paint.
- Noise Removal: At each step, the model slightly reduces the noise, guided by patterns it learned during training. This is like an artist gradually removing unnecessary strokes to reveal the underlying image.
- Iterations: This process is repeated many times. With each iteration, the image becomes clearer, more detailed, and more coherent, much like an artist continuously refining a sketch until it becomes a polished painting.
Encoder-Decoder Structure
Stable Diffusion employs an encoder-decoder structure, which can be likened to an artist first analyzing a rough sketch before refining it into etsy junk:
- Encoder: The encoder analyzes the noisy image, identifying key patterns and structures. It’s like an artist studying the initial sketch to understand its potential.
- Latent Space Representation: This analysis converts the image into a compressed format called latent space, where important features are captured. Think of it as an abstract blueprint of the final image.
- Decoder: The decoder takes this compressed information and starts reconstructing it into a detailed image. It’s akin to the artist using the blueprint to add fine details and textures, transforming the sketch into a finished artwork.
Pre-training and Fine-tuning
Before Stable Diffusion can generate high-quality images, it undergoes extensive training, similar to an artist learning different techniques and styles:
- Pre-training: The model is initially trained on a vast collection of images, learning basic patterns, textures, and structures. This phase is like an artist studying thousands of artworks to understand various styles and techniques.
- Fine-tuning: After pre-training, the model is fine-tuned for specific tasks or styles. It’s like an artist specializing in portrait painting after learning the basics. This fine-tuning allows the model to generate images with specific characteristics, like creating realistic landscapes or abstract art.
Generative Capabilities and Scalability
Stable Diffusion’s ability to generate images involves sophisticated algorithms that calculate the most likely arrangement of pixels. No hard to understand:
- Pixel Prediction: The model predicts the value of each pixel based on its surrounding pixels, ensuring the image is coherent and detailed. It’s like an artist carefully placing each brushstroke to fit the overall composition.
- Contextual Understanding: The model considers the entire context of the image, not just individual pixels. This holistic approach ensures that the final image is not only detailed but also contextually accurate.
- Scalability: The model can be scaled up by adding more layers and parameters, much like adding more tools and techniques to an artist’s repertoire. This scalability allows the model to handle more complex images and generate them faster.

How the Diffusion Process Constructs Images
Let’s delve deeper into the iterative refinement process:
- Starting Point: The process begins with an image full of random noise, essentially a chaotic mess of pixels.
- Step-by-Step Refinement: At each step, the model refines the image by reducing noise and enhancing details. Imagine an artist starting with a rough sketch and adding more details with each pass.
- Attention Mechanisms: The model uses self-attention mechanisms to focus on important parts of the image, ensuring coherence and detail. It’s like an artist deciding which areas need more attention and detail.
- Final Output: After many iterations, the model produces a final, detailed image. This is akin to the artist finishing a painting after numerous refinements, resulting in a polished masterpiece.
Deep Learning
Stable Diffusion is powered by deep learning, a type of artificial intelligence that mimics how the human brain learns.
- Neural Networks: The model uses neural networks, which are computational systems inspired by the human brain’s structure. These networks learn patterns and structures from the training data.
- Learning from Data: The model is trained on a vast amount of data, learning to recognize patterns, textures, and structures. It’s like an artist practicing by studying countless images.
- Mathematical Algorithms: Complex algorithms underpin the model’s ability to generate images. These algorithms calculate the most likely arrangement of pixels, ensuring the final image is detailed and coherent.
No Self-Attention?
Self-attention is a crucial mechanism in Stable Diffusion, allowing the model to focus on important parts of the image. Here’s how it works in detail:
- Input Embeddings: The image is broken down into pixels, each represented as a mathematical vector capturing its attributes like color and intensity.
- Query, Key, and Value Matrices: These matrices help the model understand the relationships between pixels. The Query represents the current focus, the Key provides context, and the Value offers detailed information.
- Computing Attention Scores: The model calculates attention scores to determine which pixels are most relevant. It’s like an artist deciding which areas of the canvas need more detail.
- Scaling and Normalization: These steps balance the importance of different pixels, ensuring a harmonious image. It’s akin to an artist balancing colors and contrasts.
- Contextualized Embeddings: The model combines pixels to form a contextually rich image, similar to an artist blending colors to create a cohesive painting.
- Final Output: The final image is a result of these contextualized embeddings, representing a detailed and coherent visual output.
